DSA Series: Understanding Data Structures -Part 2
March 1, 2024
Written by: Bek Johansson
In our previous chat, we delved into why learning about data structures is crucial for app efficiency, stressing how time complexity is all about counting steps, not clock time.
Today, we’re rolling up our sleeves and diving deep into the world of linear search. We’re going to untangle its complexities and understand why it’s so darn important for optimizing efficiency. Imagine a simple food array as our playground, where we’ll walk through the ins and outs of arrays and how they do their magic.
We’ll be measuring the time complexity of arrays, which means counting how many steps an operation takes. So, when you hear terms like speed, time complexity, runtime, and so on, just remember, they’re all about the number of steps it takes to get things done.
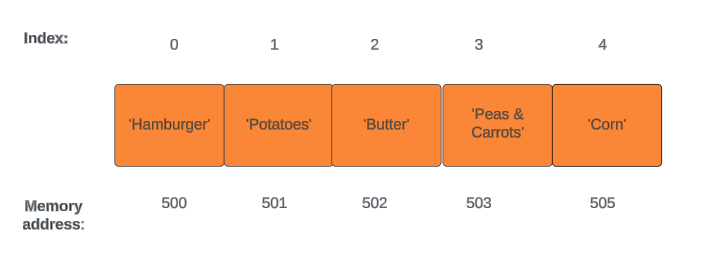
Before we jump into the nitty-gritty, let’s get a handle on how computers handle data in memory. Picture computer memory as a long line of cells, much like a row of houses on a street. Each cell holds some info, lined up one after the other. These cells, aka indexes, each have their own unique address, starting from zero and counting up like house numbers on the street.
This linear memory setup helps computers manage and access data efficiently.
Reading Operations
When it’s time to read data, the computer knows where to find it by checking the memory address. This process is usually a breeze, taking just one step since the computer can quickly grab the value stored at a specific index. But if we want to read values beyond the first one, the computer does a little simple addition to find them.
This ability to zip straight to an index and grab its value is lightning-fast. That’s what makes arrays such a powerhouse data structure — their ability to read with lightning speed.
Searching Operations
Searching is a bit like a treasure hunt. We’re on the lookout for a particular value, but we don’t know exactly where it is. Unlike reading, where we have the index in hand, searching means scanning through the array one by one until we strike gold. This linear search method might not be as efficient as reading, especially since it takes multiple steps to find what we’re after.
Insertion Operations
Adding new data can be a breeze or a bit of a puzzle. Tacking something onto the end of the array is easy — it’s just one step since the computer knows where the array ends. But slipping data in between existing elements? That takes a bit more work. We’ve got to shuffle things around to make room, especially if we’re squeezing something in at the beginning.
Deletion Operations
When we delete data, we’re left with gaps, and arrays don’t like gaps. Deleting a single index might only take one step, but closing up the holes left behind means shifting everything over. It’s like a game of musical chairs — every element has to find a new spot, which can take a few extra steps.
Analyzing Time Complexity
Understanding how many steps each operation takes in a data structure is key to picking the right tool for the job. After all, efficient data structures are the backbone of high-performing software.
Turns out, demystifying time complexity isn’t as scary as it sounds when you break it down into simple steps.
Understanding how many steps each operation takes in a data structure is key to picking the right tool for the job. After all, efficient data structures are the backbone of high-performing software.
Turns out, demystifying time complexity isn’t as scary as it sounds when you break it down into simple steps.